
Event-related Analysis#
This example can be referenced by citing the package.
This example shows how to use NeuroKit to extract epochs from data based on events localisation and its corresponding physiological signals. That way, you can compare experimental conditions with one another.
# Load NeuroKit and other useful packages
import numpy as np
import pandas as pd
import seaborn as sns
import neurokit2 as nk
The Dataset#
Use the nk.data() function to load the dataset located on NeuroKit data folder.
It contains 2.5 minutes of biosignals recorded at a frequency of 100Hz (2.5 x 60 x 100 = 15000 data points).
Biosignals : ECG, RSP, EDA + Photosensor (event signal)
# Download data
data = nk.data("bio_eventrelated_100hz")
This is the data from one participant that saw 4 emotional and neutral images from the IAPS), which we will refer to as events.
Importantly, the images were marked in the recording system (the “triggers”) by a small black rectangle on the screen, which led to the photosensor signal to go down (and then up again after the image). This is what will allow us to retrieve the location of these events.
They were 2 types of images (the condition) that were shown to the participant: “Negative” vs. “Neutral” (in terms of emotion). Each picture was presented for 3 seconds. The following list is the condition order.
condition_list = ["Negative", "Neutral", "Neutral", "Negative"]
Find Events#
These events can be localized and extracted using events_find().
Note that you should also specify whether to select events that are higher or below the threshold using the threshold_keep argument.
# Find events
events = nk.events_find(data["Photosensor"], threshold_keep="below", event_conditions=condition_list)
events
{'onset': array([ 1024, 4957, 9224, 12984]),
'duration': array([300, 300, 300, 300]),
'label': array(['1', '2', '3', '4'], dtype='<U21'),
'condition': ['Negative', 'Neutral', 'Neutral', 'Negative']}
As we can see, events_find() returns a dict containing onsets and durations for each corresponding event, based on the label for event identifiers and each event condition. Each event here lasts for 300 data points (equivalent to 3 seconds sampled at 100Hz).
# Plot the location of event with the signals
plot = nk.events_plot(events, data)
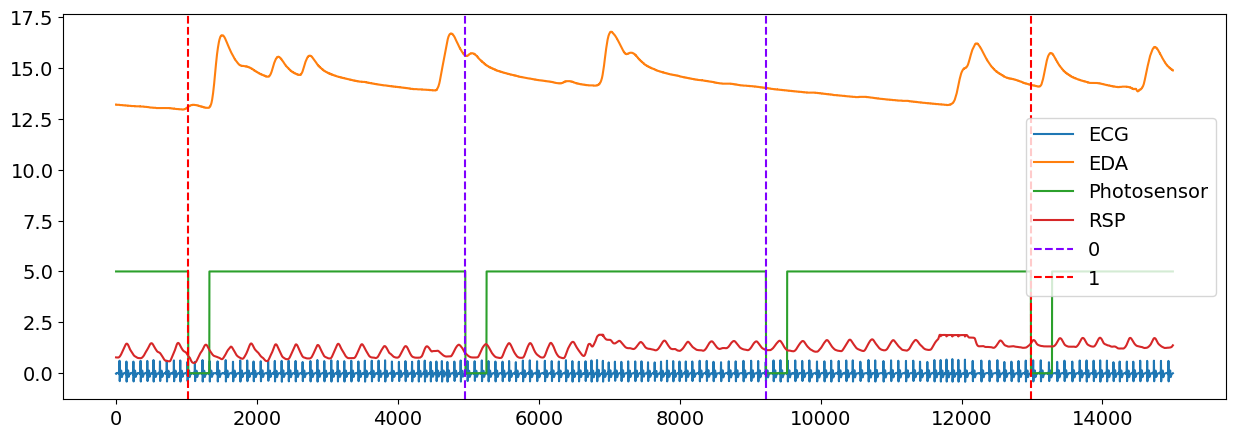
The output of events_plot() shows the corresponding events in the signal, with the blue dashed line representing a Negative event and red dashed line representing a Neutral event.
Process the Signals#
Now that we have the events location, we can go ahead and process the data.
Biosignals processing can be done quite easily using NeuroKit with the bio_process() function. Simply provide the appropriate biosignal channels and additional channels that you want to keep (for example, the photosensor), and bio_process() will take care of the rest. It will return a dataframe containing processed signals and a dictionary containing useful information.
# Process the signal
data_clean, info = nk.bio_process(
ecg=data["ECG"], rsp=data["RSP"], eda=data["EDA"], keep=data["Photosensor"], sampling_rate=100
)
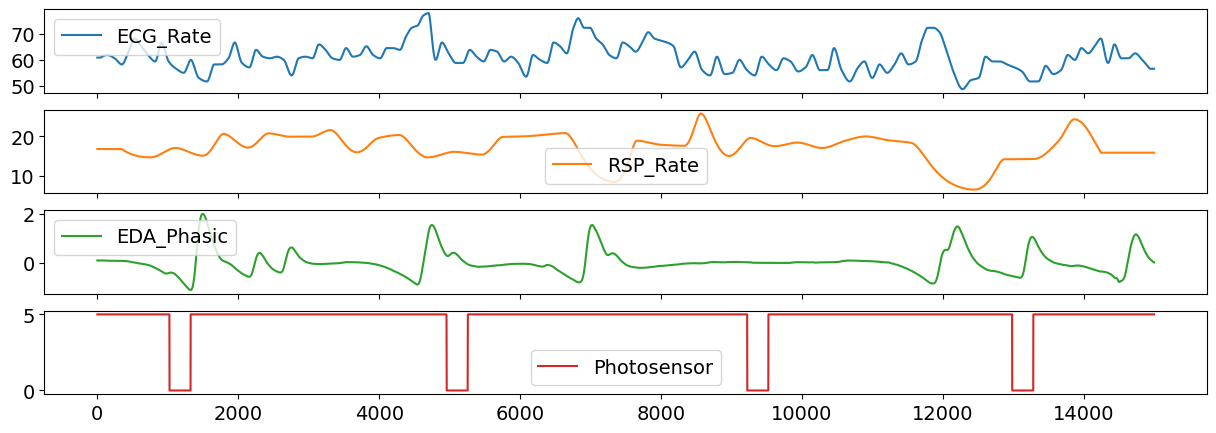
# Visualize some of the channels
data_clean[["ECG_Rate", "RSP_Rate", "EDA_Phasic", "Photosensor"]].plot(subplots=True)
array([<Axes: >, <Axes: >, <Axes: >, <Axes: >], dtype=object)
Create Epochs#
We now have to transform this dataframe into epochs, i.e. segments (chunks) of data around the events using epochs_create(). We want it to start 1 second before the event onset and end 6 seconds after. These values are passed into the epochs_start and epochs_end arguments, respectively.
Our epochs will then cover the region from -1 s to +6 s (i.e., 700 data points since the signal is sampled at 100Hz).
# Build and plot epochs
epochs = nk.epochs_create(data_clean, events, sampling_rate=100, epochs_start=-1, epochs_end=6)
Let’s plot some of the signals of the first epoch (and transform them to the same scale for visualization purposes).
# Iterate through epoch data
for epoch in epochs.values():
# Plot scaled signals
nk.signal_plot(
epoch[["ECG_Rate", "RSP_Rate", "EDA_Phasic", "Photosensor"]],
title=epoch["Condition"].values[0], # Extract condition name
standardize=True,
)
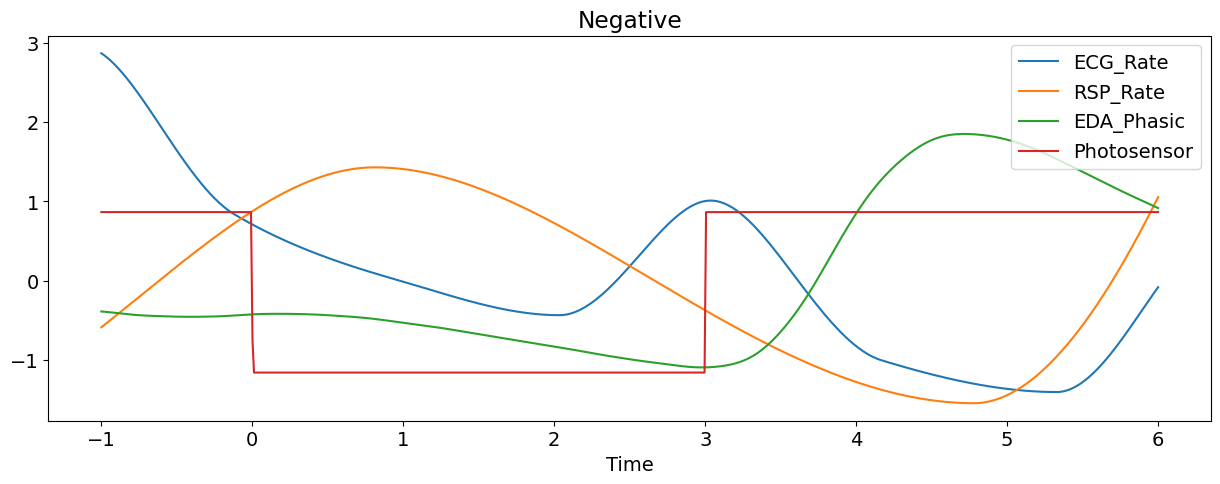
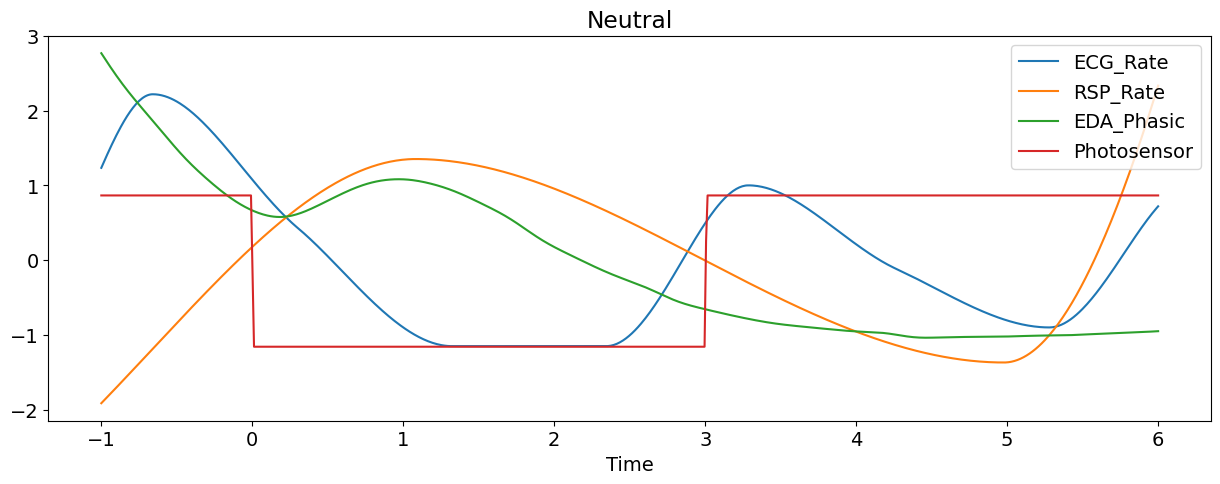
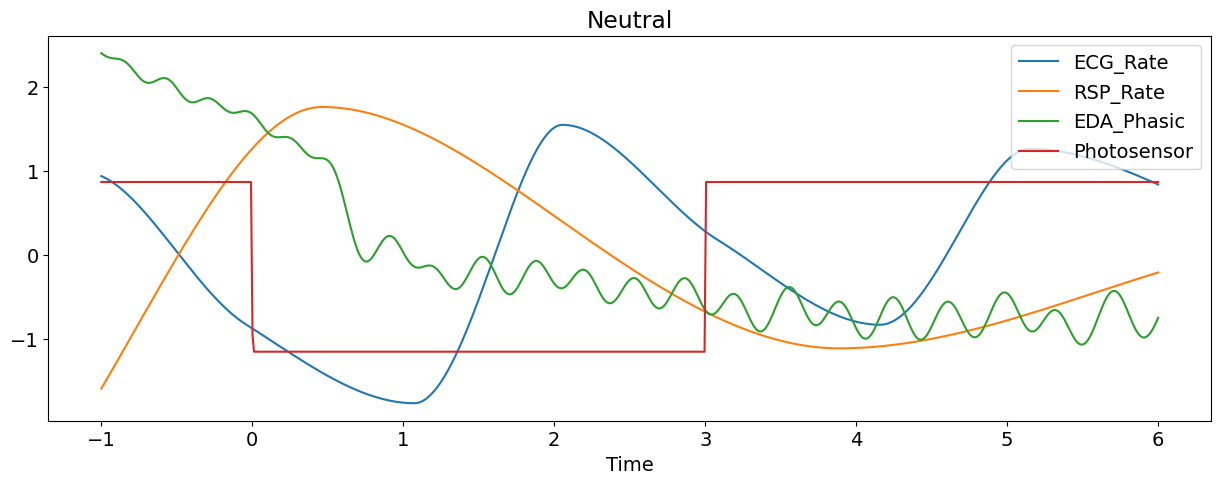
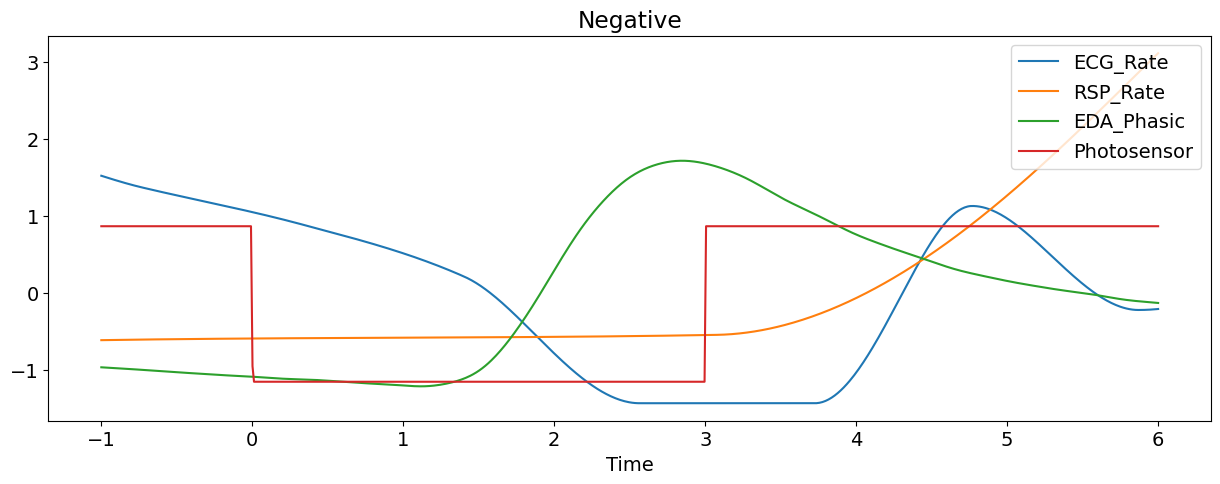
Automatic Feature Extraction#
While manual feature creation allows you to compute and extract exactly what you need, using our automated pipeline is a lot easier.
df = nk.bio_analyze(epochs, sampling_rate=100)
df
| Label | Condition | Event_Onset | ECG_Rate_Baseline | ECG_Rate_Max | ECG_Rate_Min | ECG_Rate_Mean | ECG_Rate_SD | ECG_Rate_Max_Time | ECG_Rate_Min_Time | ... | RSP_RVT_Baseline | RSP_RVT_Mean | EDA_Peak_Amplitude | EDA_SCR | SCR_Peak_Amplitude | SCR_Peak_Amplitude_Time | SCR_RiseTime | SCR_RecoveryTime | RSA_P2T | RSA_Gates | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | Negative | 1024 | 58.962843 | 1.037157 | -7.238706 | -3.416404 | 2.462046 | 3.035765 | 5.329041 | ... | 0.225643 | -0.037677 | 1.995617 | 1 | 3.114808 | 4.718169 | 1.74 | NaN | -56.170030 | -1.776357e-15 |
| 2 | 2 | Neutral | 4957 | 64.000846 | -0.056683 | -5.177317 | -3.209327 | 1.661333 | 0.011445 | 1.323319 | ... | 0.169809 | 0.019351 | 0.868942 | 0 | NaN | NaN | NaN | NaN | -43.273326 | -7.601609e-02 |
| 3 | 3 | Neutral | 9224 | 55.976284 | 5.248206 | -1.922230 | 1.891089 | 2.279224 | 2.054363 | 1.072961 | ... | 0.127095 | 0.017846 | 0.026651 | 0 | NaN | NaN | NaN | NaN | -13.138628 | 1.358487e-01 |
| 4 | 4 | Negative | 12984 | 57.505912 | 0.186396 | -5.781774 | -2.941543 | 2.142268 | 4.768240 | 2.565093 | ... | 0.080601 | 0.012434 | 1.056855 | 1 | 1.675922 | 2.845494 | 1.73 | 1.93 | -24.326239 | 1.843122e-01 |
4 rows × 46 columns
Plot Event-Related Features#
You can now plot and compare how these features differ according to the event of interest.
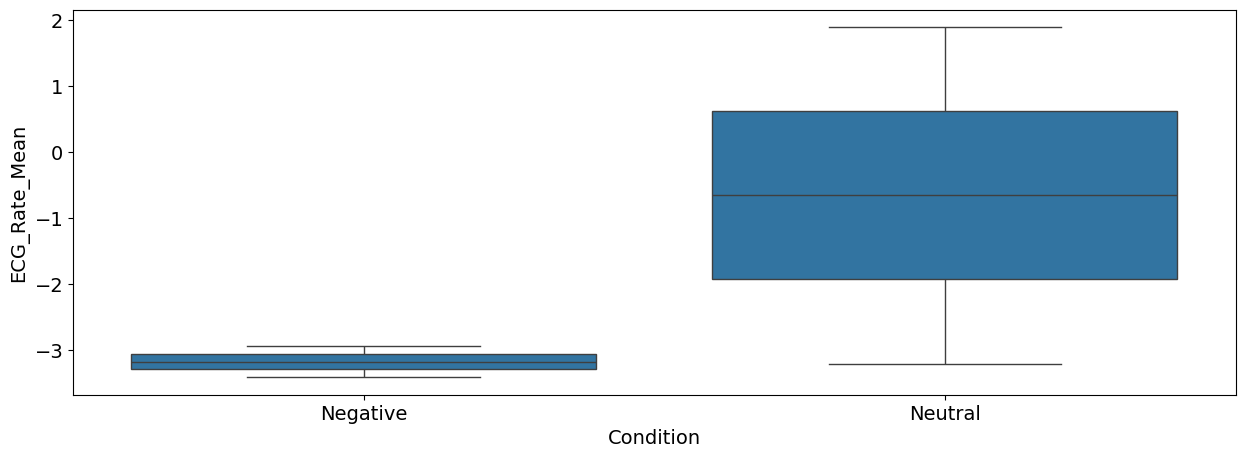
sns.boxplot(x="Condition", y="ECG_Rate_Mean", data=df);
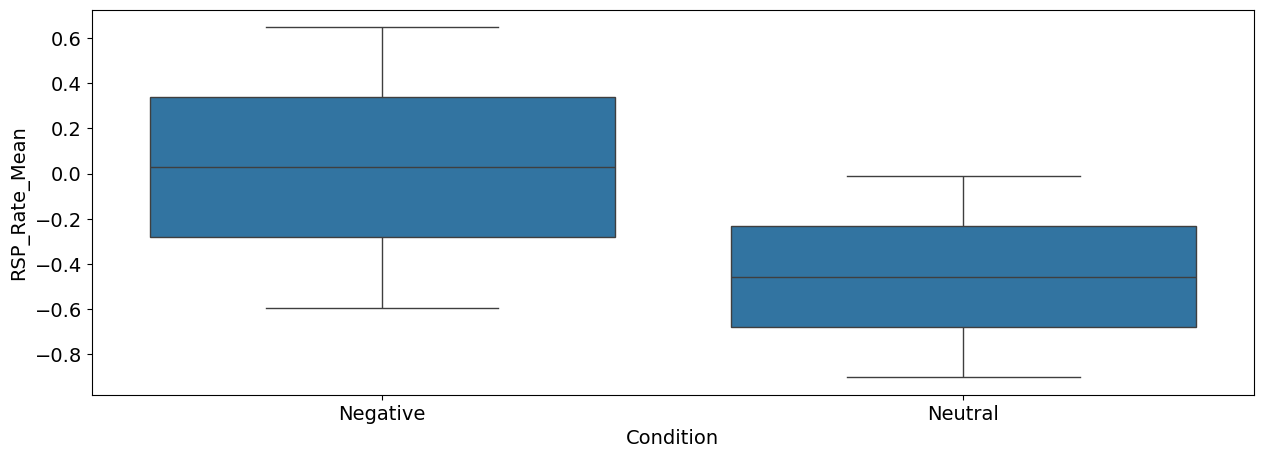
sns.boxplot(x="Condition", y="RSP_Rate_Mean", data=df);
sns.boxplot(x="Condition", y="EDA_Peak_Amplitude", data=df);
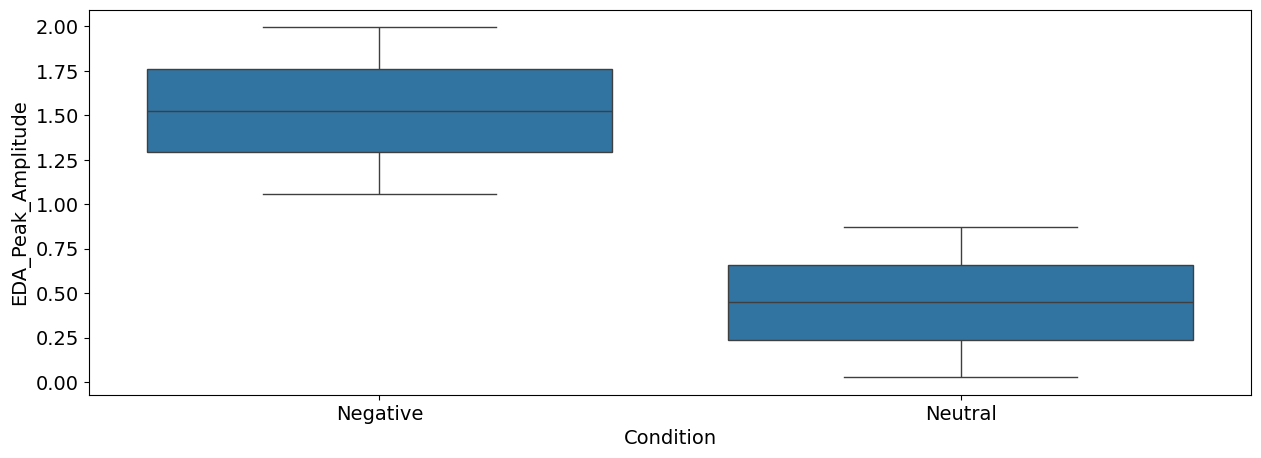
Interpretation: As we can see, there seems to be a difference between the negative and the neutral pictures. Negative stimuli, as compared to neutral stimuli, were related to a stronger cardiac deceleration (i.e., higher heart rate variability), an accelerated breathing rate, and higher SCR magnitude.
Of course, because of data size limits on Github, we had to downsample the signals and have only one participant with a few events. That said, the same workflow can apply for more events, and more participants (you just need to additionally loop through all participants).