PPG#
Main#
ppg_process()#
- ppg_process(ppg_signal, sampling_rate=1000, method='elgendi', method_quality='templatematch', report=None, **kwargs)[source]#
Process a photoplethysmogram (PPG) signal
Convenience function that automatically processes a photoplethysmogram signal.
- Parameters:
ppg_signal (Union[list, np.array, pd.Series]) – The raw PPG channel.
sampling_rate (int) – The sampling frequency of
ppg_signal()(in Hz, i.e., samples/second).method (str) – The processing pipeline to apply. Can be one of
"elgendi". Defaults to"elgendi".method_quality (str) – The quality assessment approach to use. Can be one of
"templatematch","disimilarity". Defaults to"templatematch".report (str) – The filename of a report containing description and figures of processing (e.g.
"myreport.html"). Needs to be supplied if a report file should be generated. Defaults toNone. Can also be"text"to just print the text in the console without saving anything.**kwargs – Other arguments to be passed to specific methods. For more information, see
ppg_methods().
- Returns:
signals (DataFrame) – A DataFrame of same length as
ppg_signal()containing the following columns:PPG_Raw: The raw signal.PPG_Clean: The cleaned signal.PPG_Rate: The heart rate as measured based on PPG peaks.PPG_Peaks: The PPG peaks marked as “1” in a list of zeros.
info (dict) – A dictionary containing the information of peaks and the signals’ sampling rate.
See also
Examples
In [1]: import neurokit2 as nk In [2]: ppg = nk.ppg_simulate(duration=10, sampling_rate=1000, heart_rate=70) In [3]: signals, info = nk.ppg_process(ppg, sampling_rate=1000) In [4]: nk.ppg_plot(signals, info)
ppg_analyze()#
- ppg_analyze(data, sampling_rate=1000, method='auto')[source]#
Photoplethysmography (PPG) Analysis.
Performs PPG analysis on either epochs (event-related analysis) or on longer periods of data such as resting-state data.
- Parameters:
data (Union[dict, pd.DataFrame]) – A dictionary of epochs, containing one DataFrame per epoch, usually obtained via
epochs_create(), or a DataFrame containing all epochs, usually obtained viaepochs_to_df(). Can also take a DataFrame of processed signals from a longer period of data, typically generated byppg_process()orbio_process(). Can also take a dict containing sets of separate periods of data.sampling_rate (int) – The sampling frequency of the signal (in Hz, i.e., samples/second). Defaults to 1000Hz.
method (str) – Can be one of
"event-related"for event-related analysis on epochs, or"interval-related"for analysis on longer periods of data. Defaults to"auto"where the right method will be chosen based on the mean duration of the data ("event-related"for duration under 10s).
- Returns:
DataFrame – A dataframe containing the analyzed PPG features. If event-related analysis is conducted, each epoch is indicated by the
Labelcolumn. Seeppg_eventrelated()andppg_intervalrelated()docstrings for details.
See also
bio_process,ppg_process,epochs_create,ppg_eventrelated,ppg_intervalrelatedExamples
In [1]: import neurokit2 as nk # Example 1: Simulate data for event-related analysis In [2]: ppg = nk.ppg_simulate(duration=20, sampling_rate=1000) # Process data In [3]: ppg_signals, info = nk.ppg_process(ppg, sampling_rate=1000) In [4]: epochs = nk.epochs_create(ppg_signals, events=[5000, 10000, 15000], ...: epochs_start=-0.1, epochs_end=1.9) ...: # Analyze In [5]: analyze_epochs = nk.ppg_analyze(epochs, sampling_rate=1000) In [6]: analyze_epochs Out[6]: Label Event_Onset ... PPG_Rate_Trend_Quadratic PPG_Rate_Trend_R2 1 1 5000 ... 1.090039 0.663261 2 2 10000 ... -4.357093 0.886317 3 3 15000 ... 0.178681 0.469490 [3 rows x 12 columns] # Example 2: Download the resting-state data In [7]: data = nk.data("bio_resting_5min_100hz") # Process the data In [8]: df, info = nk.ppg_process(data["PPG"], sampling_rate=100) # Analyze In [9]: analyze_df = nk.ppg_analyze(df, sampling_rate=100) In [10]: analyze_df Out[10]: PPG_Rate_Mean ... HRV_Symbolic_EqualProb4_2UV 0 86.401345 ... 0.109557 [1 rows x 96 columns]
ppg_simulate()#
- ppg_simulate(duration=120, sampling_rate=1000, heart_rate=70, frequency_modulation=0.2, ibi_randomness=0.1, drift=0, motion_amplitude=0.1, powerline_amplitude=0.01, burst_number=0, burst_amplitude=1, random_state=None, random_state_distort='spawn', show=False)[source]#
Simulate a photoplethysmogram (PPG) signal
Phenomenological approximation of PPG. The PPG wave is described with four landmarks: wave onset, location of the systolic peak, location of the dicrotic notch and location of the diastolic peaks. These landmarks are defined as x and y coordinates (in a time series). These coordinates are then interpolated at the desired sampling rate to obtain the PPG signal.
- Parameters:
duration (int) – Desired recording length in seconds. The default is 120.
sampling_rate (int) – The desired sampling rate (in Hz, i.e., samples/second). The default is 1000.
heart_rate (int) – Desired simulated heart rate (in beats per minute). The default is 70. Note that for the ECGSYN method, random fluctuations are to be expected to mimic a real heart rate. These fluctuations can cause some slight discrepancies between the requested heart rate and the empirical heart rate, especially for shorter signals.
frequency_modulation (float) – Float between 0 and 1. Determines how pronounced respiratory sinus arrythmia (RSA) is (0 corresponds to absence of RSA). The default is 0.3.
ibi_randomness (float) – Float between 0 and 1. Determines how much random noise there is in the duration of each PPG wave (0 corresponds to absence of variation). The default is 0.1.
drift (float) – Float between 0 and 1. Determines how pronounced the baseline drift (.05 Hz) is (0 corresponds to absence of baseline drift). The default is 1.
motion_amplitude (float) – Float between 0 and 1. Determines how pronounced the motion artifact (0.5 Hz) is (0 corresponds to absence of motion artifact). The default is 0.1.
powerline_amplitude (float) – Float between 0 and 1. Determines how pronounced the powerline artifact (50 Hz) is (0 corresponds to absence of powerline artifact). Note that powerline_amplitude > 0 is only possible if
sampling_rateis >= 500. The default is 0.1.burst_amplitude (float) – Float between 0 and 1. Determines how pronounced high frequency burst artifacts are (0 corresponds to absence of bursts). The default is 1.
burst_number (int) – Determines how many high frequency burst artifacts occur. The default is 0.
show (bool) – If
True, returns a plot of the landmarks and interpolated PPG. Useful for debugging.random_state (None, int, numpy.random.RandomState or numpy.random.Generator) – Seed for the random number generator. See for
misc.check_random_statefor further information.random_state_distort ({‘legacy’, ‘spawn’}, None, int, numpy.random.RandomState or numpy.random.Generator) – Random state to be used to distort the signal. If
"legacy", use the same random state used to generate the signal (discouraged as it creates dependent random streams). If"spawn", spawn independent children random number generators from the random_state argument. If any of the other types, generate independent children random number generators from the random_state_distort provided (this allows generating multiple version of the same signal distorted by different random noise realizations).
- Returns:
ppg (array) – A vector containing the PPG.
See also
ecg_simulate,rsp_simulate,eda_simulate,emg_simulateExamples
In [1]: import neurokit2 as nk In [2]: ppg = nk.ppg_simulate(duration=40, sampling_rate=500, heart_rate=75, random_state=42)
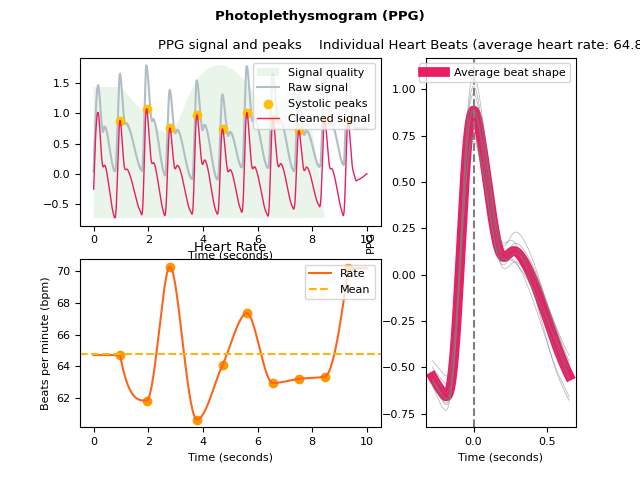
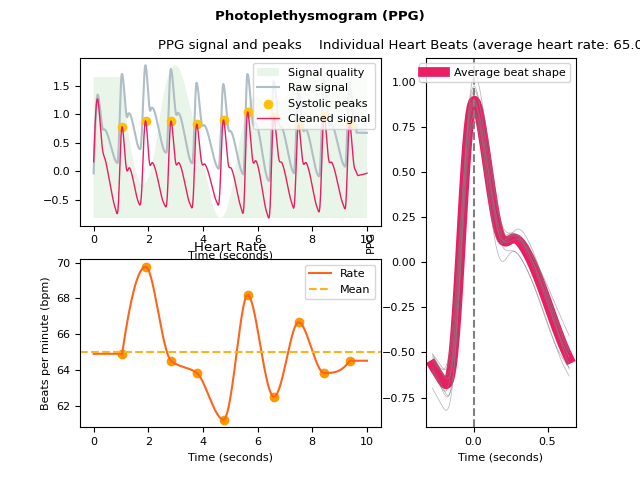
ppg_plot()#
- ppg_plot(ppg_signals, info=None, static=True)[source]#
Visualize photoplethysmogram (PPG) data
Visualize the PPG signal processing.
- Parameters:
ppg_signals (DataFrame) – DataFrame obtained from
ppg_process().info (dict) – The information Dict returned by
ppg_process(). Defaults toNone.static (bool) – If True, a static plot will be generated with matplotlib. If False, an interactive plot will be generated with plotly. Defaults to True.
- Returns:
See
ecg_plot()for details on how to access the figure, modify the size and save it.
See also
Examples
In [1]: import neurokit2 as nk # Simulate data In [2]: ppg = nk.ppg_simulate(duration=10, sampling_rate=100, heart_rate=70) # Process signal In [3]: signals, info = nk.ppg_process(ppg, sampling_rate=100) # Plot In [4]: nk.ppg_plot(signals, info)
Preprocessing#
ppg_clean()#
- ppg_clean(ppg_signal, sampling_rate=1000, heart_rate=None, method='elgendi')[source]#
Clean a photoplethysmogram (PPG) signal
Clean a raw PPG signal for analysis by filtering to remove noise. This improves the accuracy of subsequent analyses, such as systolic peak detection.
'elgendi'(default): Bandpass filter the signal between 0.5 and 8 Hz using a Butterworth filter.'nabian2018': Lowpass filter the signal below 40 Hz. If heart_rate is provided then the function checks whether 40 Hz is at least 10 times the cardiac frequency and less than half of the sampling frequency, and raises an error if not.'langevin2021': Bandpass filter between 0.7 and 3.5 Hz using a second-order Butterworth filter, applied by Langevin et al. (2021) and Vorreuther et al. (2025) in an EmotiBit wearable PPG validation study. Note that these filter parameters were not systematically optimized — they reflect the pipeline used in a specific device-validation context. The upper cutoff (3.5 Hz) is narrower than'elgendi'(8 Hz), which may attenuate higher-frequency components. This method should be used primarily for research purposes until further validation is conducted.'goda2024': Bandpass filter the signal between 0.5 and 12 Hz using a fourth-order Chebyshev Type II filter.
- Parameters:
ppg_signal (Union[list, np.array, pd.Series]) – The raw PPG channel.
heart_rate (Union[int, float]) – The heart rate of the PPG signal. Applicable only if method is
"nabian2018"to check that filter frequency is appropriate.sampling_rate (int) – The sampling frequency of
ppg_signal(in Hz, i.e., samples/second). The default is 1000.method (str) – The processing pipeline to apply. Can be one of
"elgendi"(default),"nabian2018","langevin2021","goda2024", or"none". If"none"is passed, the raw signal will be returned without any cleaning.
- Returns:
clean (array) – A vector containing the cleaned PPG.
See also
Examples
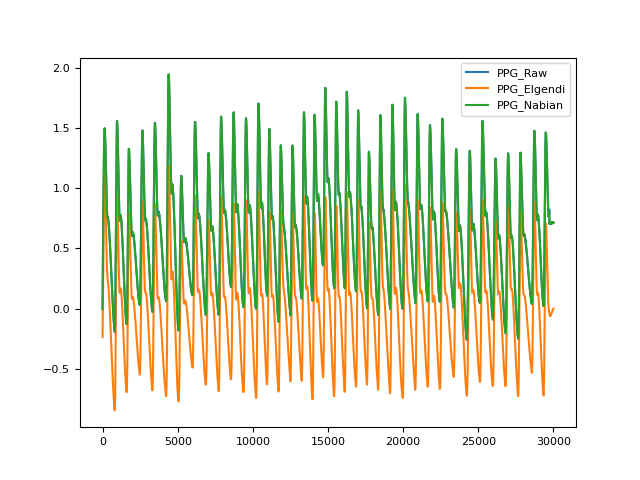
In [1]: import neurokit2 as nk In [2]: import pandas as pd In [3]: import matplotlib.pyplot as plt # Simulate and clean signal In [4]: ppg = nk.ppg_simulate(heart_rate=75, duration=30) In [5]: ppg_elgendi = nk.ppg_clean(ppg, method='elgendi') In [6]: ppg_nabian = nk.ppg_clean(ppg, method='nabian2018', heart_rate=75) In [7]: ppg_langevin = nk.ppg_clean(ppg, method='langevin2021') # Plot and compare methods In [8]: signals = pd.DataFrame({'PPG_Raw' : ppg, ...: 'PPG_Elgendi' : ppg_elgendi, ...: 'PPG_Nabian' : ppg_nabian, ...: 'PPG_Langevin' : ppg_langevin}) ...: In [9]: signals.plot() Out[9]: <Axes: >
References
Nabian, M., Yin, Y., Wormwood, J., Quigley, K. S., Barrett, L. F., & Ostadabbas, S. (2018). An open-source feature extraction tool for the analysis of peripheral physiological data. IEEE Journal of Translational Engineering in Health and Medicine, 6, 1-11.
Langevin, A., Bégin, W., Lavallière, M., Beaulieu, L.-D., Menelas, B.-D. J., Gaboury, S., et al. (2021). “Criterion validation of an open-source wearable physiological sensors device,” in Proceedings of the 9th International Conference on Sport Sciences Research and Technology Support – icSPORTS (SciTePress), 95–105.
Vorreuther, A., Tagalidou, N., & Vukelić, M. (2025). Validation of the EmotiBit wearable sensor for heart-based measures under varying workload conditions. Front Neuroergonomics, 6, 1585469.
M. Elgendi, I. Norton, M. Brearley, D. Abbott, and D. Schuurmans (2013). Systolic peak detection in acceleration photoplethysmograms measured from emergency responders in tropical conditions. PLoS ONE, 8(10), 1–11.
M.A. Goda, P.H. Charlton, and J. Behar (2024). pyPPG: a Python toolbox for comprehensive photoplethysmography signal analysis. Physiological Measurement, 45 (4), 045001. doi: https://doi.org/10.1088/1361-6579/ad33a2
ppg_peaks()#
- ppg_peaks(ppg_cleaned, sampling_rate=1000, method='elgendi', correct_artifacts=False, show=False, **kwargs)[source]#
Find systolic peaks in a photoplethysmogram (PPG) signal
Find the peaks in a PPG signal using the specified method. You can pass an unfiltered PPG signal as input, but typically a filtered PPG (cleaned using
ppg_clean()) will provide better results.Methods available (see ppg_findpeaks for details):
"elgendi": Method by Elgendi et al. (2013), based on moving average and thresholding."bishop": Method by Bishop & Ercole (2018), multi-scale peak and trough detection. Returns pulse onsets as well as peaks."charlton": MSPTDfastv2 method by Charlton et al. (2025). Uses an efficient multi-scale peak and trough detection algorithm. Returns pulse onsets as well as peaks."charlton2024": MSPTDfastv1 method by Charlton et al. (2024). Returns pulse onsets as well as peaks. Uses an efficient multi-scale peak and trough detection algorithm. Now superseded by v2 (i.e.charlton).
- Parameters:
ppg_cleaned (Union[list, np.array, pd.Series]) – The cleaned PPG channel as returned by
ppg_clean().sampling_rate (int) – The sampling frequency of
ppg_cleaned(in Hz, i.e., samples/second). Defaults to 1000.method (str) – The processing pipeline to apply. Can be one of
"elgendi","bishop","charlton", or"charlton2024". The default is"elgendi".correct_artifacts (bool) – Whether or not to identify and fix artifacts, using the method by Lipponen & Tarvainen (2019).
show (bool) – If
True, will show a plot of the signal with peaks. Defaults toFalse.**kwargs – Additional keyword arguments, usually specific for each method.
- Returns:
signals (DataFrame) – A DataFrame of same length as the input signal in which occurrences of peaks marked as
1in a list of zeros with the same length asppg_cleaned. Accessible with the keys"PPG_Peaks".info (dict) – A dictionary containing additional information, in this case the samples at which peaks occur, accessible with the key
"PPG_Peaks", as well as the signals’ sampling rate, accessible with the key"sampling_rate".
See also
ppg_clean,ppg_fixpeaks,signal_fixpeaks,ppg_findpeaksExamples
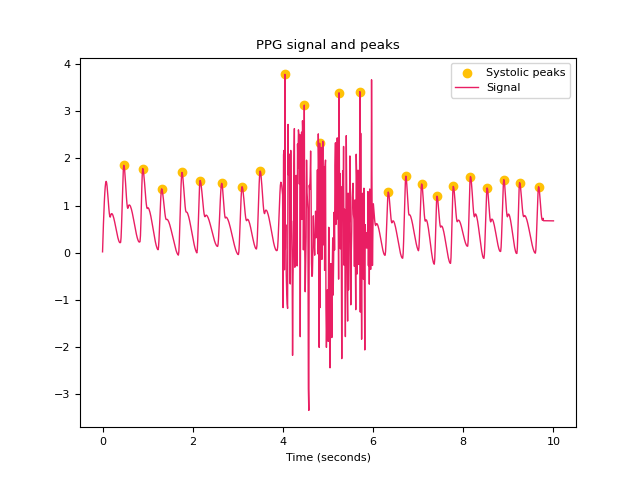
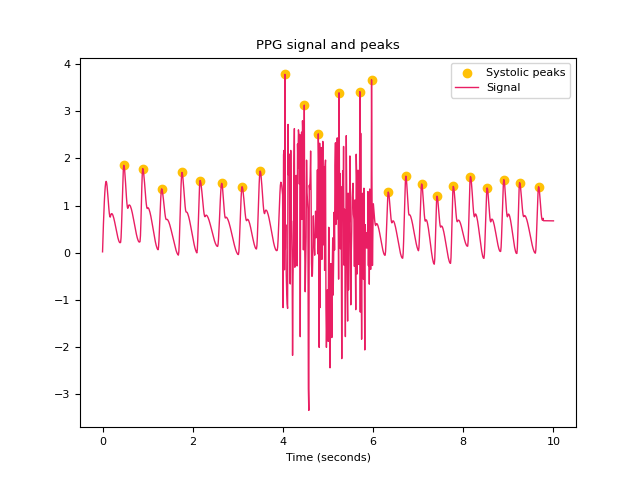
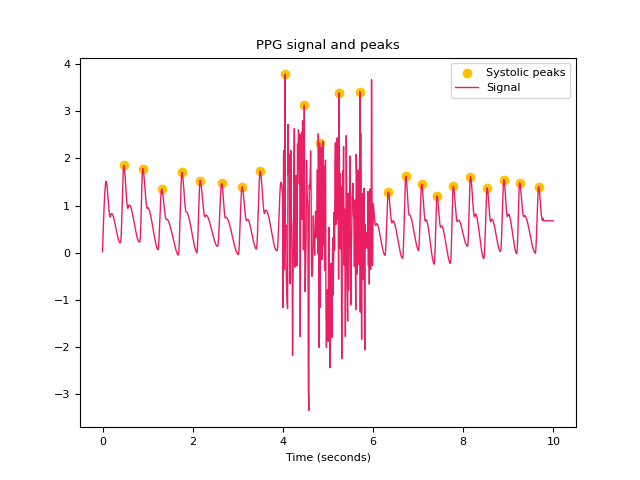
In [1]: import neurokit2 as nk In [2]: import numpy as np In [3]: ppg = nk.ppg_simulate(heart_rate=75, duration=20, sampling_rate=50) In [4]: ppg[400:600] = ppg[400:600] + np.random.normal(0, 1.25, 200) # Default method (Elgendi et al., 2013) In [5]: peaks, info = nk.ppg_peaks(ppg, sampling_rate=100, method="elgendi", show=True) In [6]: info["PPG_Peaks"] Out[6]: array([ 46, 88, 132, 176, 218, 263, 306, 349, 394, 437, 474, 513, 557, 598, 633, 671, 742, 778, 815, 853, 887, 926, 964]) # Method by Bishop et al., (2018) In [7]: peaks, info = nk.ppg_peaks(ppg, sampling_rate=100, method="bishop", show=True) # Correct artifacts In [8]: peaks, info = nk.ppg_peaks(ppg, sampling_rate=100, correct_artifacts=True, show=True)
References
Elgendi, M., Norton, I., Brearley, M., Abbott, D., & Schuurmans, D. (2013). Systolic peak detection in acceleration photoplethysmograms measured from emergency responders in tropical conditions. PloS one, 8(10), e76585.
Bishop, S. M., & Ercole, A. (2018). Multi-scale peak and trough detection optimised for periodic and quasi-periodic neuroscience data. In Intracranial Pressure & Neuromonitoring XVI (pp. 189-195). Springer International Publishing.
Charlton, P. H. et al. (2025). The MSPTDfast photoplethysmography beat detection algorithm: design, benchmarking, and open-source distribution. Physiological Measurement, 46, 035002.
Charlton, P. H. et al. (2024). MSPTDfast: An Efficient Photoplethysmography Beat Detection Algorithm. Proc CinC.
Analysis#
Miscellaneous#
ppg_findpeaks()#
- ppg_findpeaks(ppg_cleaned, sampling_rate=1000, method='elgendi', show=False, **kwargs)[source]#
Find systolic peaks in a photoplethysmogram (PPG) signal
Low-level function used by
ppg_peaks()to identify peaks in a PPG signal using a different set of algorithms. Use the main function and see its documentation for details.- Parameters:
ppg_cleaned (Union[list, np.array, pd.Series]) – The cleaned PPG channel as returned by
ppg_clean().sampling_rate (int) – The sampling frequency of the PPG (in Hz, i.e., samples/second). The default is 1000.
method (str) – The processing pipeline to apply. Can be one of
"elgendi","bishop". The default is"elgendi".show (bool) – If
True, returns a plot of the thresholds used during peak detection. Useful for debugging. The default isFalse.
- Returns:
info (dict) – A dictionary containing additional information, in this case the samples at which systolic peaks occur, accessible with the key
"PPG_Peaks".
See also
Examples
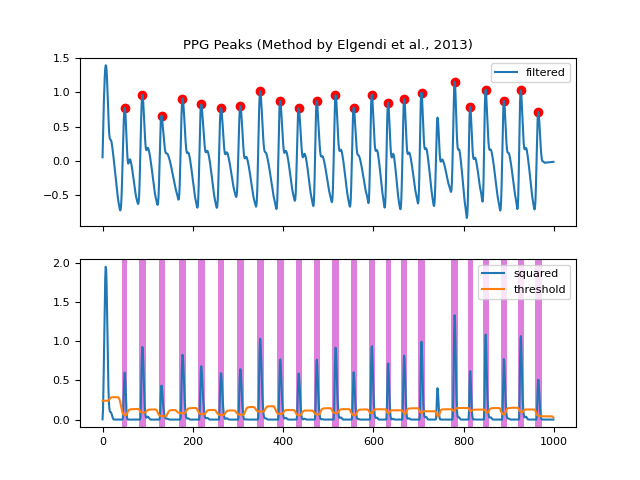
In [1]: import neurokit2 as nk In [2]: import matplotlib.pyplot as plt In [3]: ppg = nk.ppg_simulate(heart_rate=75, duration=20, sampling_rate=50) In [4]: ppg_clean = nk.ppg_clean(ppg, sampling_rate=50) In [5]: peaks = nk.ppg_findpeaks(ppg_clean, sampling_rate=100, show=True) # Method by Bishop et al., (2018) In [6]: peaks = nk.ppg_findpeaks(ppg, method="bishop", show=True)
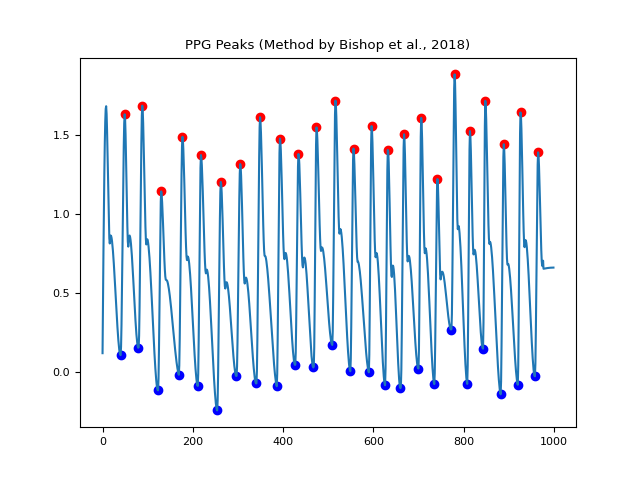
References
Elgendi, M., Norton, I., Brearley, M., Abbott, D., & Schuurmans, D. (2013). Systolic peak detection in acceleration photoplethysmograms measured from emergency responders in tropical conditions. PloS one, 8(10), e76585.
Bishop, S. M., & Ercole, A. (2018). Multi-scale peak and trough detection optimised for periodic and quasi-periodic neuroscience data. In Intracranial Pressure & Neuromonitoring XVI (pp. 189-195). Springer International Publishing.
Charlton, P. H. et al. (2025). The MSPTDfast photoplethysmography beat detection algorithm: design, benchmarking, and open-source distribution. Physiological Measurement, 46, 035002.
Charlton, P. H. et al. (2024). MSPTDfast: An Efficient Photoplethysmography Beat Detection Algorithm. Proc CinC.
Any function appearing below this point is not explicitly part of the documentation and should be added. Please open an issue if there is one.
Submodule for NeuroKit.
- ppg_methods(sampling_rate=1000, method='elgendi', method_cleaning='default', method_peaks='default', method_quality='default', **kwargs)[source]#
PPG Preprocessing Methods
This function analyzes and specifies the methods used in the preprocessing, and create a textual description of the methods used. It is used by
ppg_process()to dispatch the correct methods to each subroutine of the pipeline andppg_report()to create a preprocessing report.- Parameters:
sampling_rate (int) – The sampling frequency of the raw PPG signal (in Hz, i.e., samples/second).
method (str) – The method used for cleaning and peak finding if
"method_cleaning"and"method_peaks"are set to"default". Can be one of"elgendi". Defaults to"elgendi".method_cleaning (str) – The method used to clean the raw PPG signal. If
"default", will be set to the value of"method". Defaults to"default". For more information, see the"method"argument ofppg_clean().method_peaks (str) – The method used to find peaks. If
"default", will be set to the value of"method". Defaults to"default". For more information, see the"method"argument ofppg_findpeaks().method_quality (str) – The method used to assess PPG signal quality. If
"default", will be set to the value of"templatematch". Defaults to"templatematch". For more information, see the"method"argument ofppg_quality().**kwargs – Other arguments to be passed to
ppg_clean()andppg_findpeaks().
- Returns:
report_info (dict) – A dictionary containing the keyword arguments passed to the cleaning and peak finding functions, text describing the methods, and the corresponding references.
See also
Examples
In [1]: import neurokit2 as nk In [2]: methods = nk.ppg_methods( ...: sampling_rate=100, method="elgendi", ...: method_cleaning="nabian2018", method_quality="templatematch") ...: In [3]: print(methods["text_cleaning"]) was preprocessed using a lowpass filter (with a cutoff frequency of 40 Hz, butterworth 2nd order; following Nabian et al., 2018). In [4]: print(methods["references"][0]) Elgendi M, Norton I, Brearley M, Abbott D, Schuurmans D (2013) Systolic Peak Detection in Acceleration Photoplethysmograms Measured from Emergency Responders in Tropical Conditions PLoS ONE 8(10): e76585. doi:10.1371/journal.pone.0076585.
- ppg_quality(ppg_cleaned, peaks=None, sampling_rate=1000, method='templatematch', window_sec=None, overlap_sec=None, no_bins=16, ppg_raw=None)[source]#
PPG Signal Quality Assessment
Assess the quality of the PPG Signal using various methods:
The
"templatematch"method (loosely based on Orphanidou et al., 2015) computes a continuous index of quality of the PPG signal, by calculating the correlation coefficient between each individual pulse wave and an average (template) pulse wave shape. This index is therefore relative: 1 corresponds to pulse waves that are closest to the average pulse wave shape (i.e. correlate exactly with it) and 0 corresponds to there being no correlation with the average pulse wave shape.The
"dissimilarity"method (loosely based on Sabeti et al., 2019) computes a continuous index of quality of the PPG signal, by calculating the level of dissimilarity between each individual pulse wave and an average (template) pulse wave shape (after they are normalised). A value of zero indicates no dissimilarity (i.e. equivalent pulse wave shapes), whereas values above or below indicate increasing dissimilarity. The original method used dynamic time-warping to align the pulse waves prior to calculating the level of dsimilarity, whereas this implementation does not currently include this step.The
"ho2025"method (Ho et al., 2025) assesses PPG quality on a beat-by-beat basis by predicting whether each interbeat-interval (IBI) is accurate. To do so, beats are detected using a primary beat detector, and each IBI is predicted to be accurate only if a secondary beat detector detects beats in the same positions (within a tolerance). In this implementation, all signal samples within an IBI are rated as high quality (1) if that IBI is predicted to be accurate, or low quality (0) if that IBI is predicted to be inaccurate. Ho et al. proposed this approach for the ECG, and here it has been applied to the PPG. The general approach was derived by Ho et al from the previously proposed bSQI approach.The
"skewness"method (based on Selveraj, 2011 and Elgendi, 2016) computes the skewness of the PPG signal. The skewness is a measure of the asymmetry of the probability distribution of the signal’s amplitude values. In Elgendi (2016), higher quality signals were generally found to have higher skewness values.The
"kurtosis"method (based on Selveraj, 2011 and Elgendi, 2016) computes the kurtosis of the PPG signal. The kurtosis is a measure of the “tailedness” of the probability distribution of the signal’s amplitude values. In Elgendi (2016), higher quality signals were generally found to have higher kurtosis values.The
"entropy"method (based on Selvaraj et al., 2011, and inspired by Elgendi, 2016) computes the entropy of the signal in moving windows. The entropy is a measure of the randomness in the signal’s amplitude values.The
"perfusion"method (based on Elgendi, 2016) computes the perfusion index of the PPG signal. The perfusion index is the ratio of the amplitude of the pulsatile (AC) component of the PPG to its baseline (DC) amplitude, expressed as a percentage. It is calculated over moving windows (default: 3 seconds window, 2 seconds overlap). Requires raw PPG signal.The
"relative_power"method (based on Elgendi, 2016) computes the relative power of the PPG signal. The relative power is the ratio of the power in the 1-2.25 Hz band to the power in the 0-8 Hz band, giving a value between 0 and 1. It is calculated over moving windows (default: 60 seconds window, 30 seconds overlap). Requires raw PPG signal.
- Parameters:
ppg_cleaned (Union[list, np.array, pd.Series]) – The cleaned PPG signal in the form of a vector of values.
peaks (tuple or list) – The list of PPG pulse wave peak samples returned by
ppg_peaks(). If None, peaks is computed from the signal input.sampling_rate (int) – The sampling frequency of the signal (in Hz, i.e., samples/second).
method (str) – The method for computing PPG signal quality, can be
"templatematch"(default),"dissimilarity","ho2025","skewness","kurtosis","entropy","perfusion", or"relative_power".window_sec (float, optional) – Window length in seconds for windowed metrics. Default is 3 seconds for
"skewness","kurtosis","perfusion", and 60 seconds for"relative_power".overlap_sec (float, optional) – Overlap between windows in seconds for windowed metrics. Default is 2 seconds for
"skewness","kurtosis","perfusion", and 30 seconds for"relative_power".no_bins (int, optional) – Number of bins for
"entropy"calculation (default: 16).ppg_raw (Union[list, np.array, pd.Series], optional) – The raw PPG signal: used for the
"perfusion"and"relative_power"methods.
- Returns:
quality (array) – Vector containing the quality index ranging from 0 to 1 for
"templatematch"method, or an unbounded value (where 0 indicates high quality) for"dissimilarity"method, or zeros and ones (where 1 indicates high quality) for"ho2025"method, or an unbounded value for"skewness","kurtosis", or"entropy", or a value between 0 and 100% for"perfusion"method (100% being high quality), or a value between 0 and 1 for"relative_power"method.
See also
signal_quality,ppg_cleanReferences
Orphanidou, C. et al. (2015). “Signal-quality indices for the electrocardiogram and photoplethysmogram: derivation and applications to wireless monitoring”. IEEE Journal of Biomedical and Health Informatics, 19(3), 832-8.
Sabeti E. et al. (2019). Signal quality measure for pulsatile physiological signals using morphological features: Applications in reliability measure for pulse oximetry. Informatics in Medicine Unlocked, 16, 100222.
Ho, S.Y.S et al. (2025). “Accurate RR-interval extraction from single-lead, telehealth electrocardiogram signals. medRxiv, 2025.03.10.25323655. https://doi.org/10.1101/2025.03.10.25323655
Elgendi, M. et al. (2016). “Optimal signal quality index for photoplethysmogram signals”. Bioengineering, 3(4), 1–15. doi: https://doi.org/10.3390/bioengineering3040021
Selvaraj, N. et al. (2011). “Statistical approach for the detection of motion/noise artifacts in Photoplethysmogram”. Proc IEEE EMBC; pp. 4972–4975.
Examples
Example 1: ‘templatematch’ method
In [1]: import neurokit2 as nk In [2]: sampling_rate = 100 In [3]: ppg = nk.ppg_simulate(duration=30, sampling_rate=sampling_rate, heart_rate=80) In [4]: ppg_cleaned = nk.ppg_clean(ppg, sampling_rate=sampling_rate) In [5]: quality = nk.ppg_quality(ppg_cleaned, sampling_rate=sampling_rate, method="templatematch") In [6]: nk.signal_plot([ppg_cleaned, quality], standardize=True)
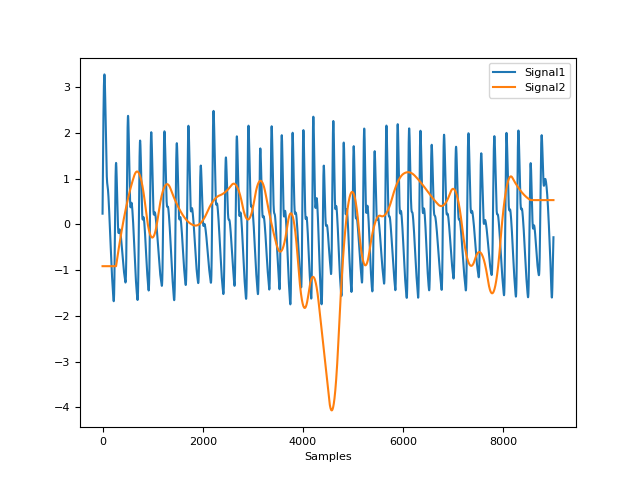
Example 2: ‘skewness’ method
In [7]: import neurokit2 as nk In [8]: sampling_rate = 100 In [9]: ppg = nk.ppg_simulate(duration=30, sampling_rate=sampling_rate, heart_rate=80) In [10]: ppg_cleaned = nk.ppg_clean(ppg, sampling_rate=sampling_rate) In [11]: quality = nk.ppg_quality(ppg_cleaned, sampling_rate=sampling_rate, method="skewness", window_sec=3, overlap_sec=2) In [12]: nk.signal_plot([ppg_cleaned, quality], standardize=True) In [13]: plt.close()
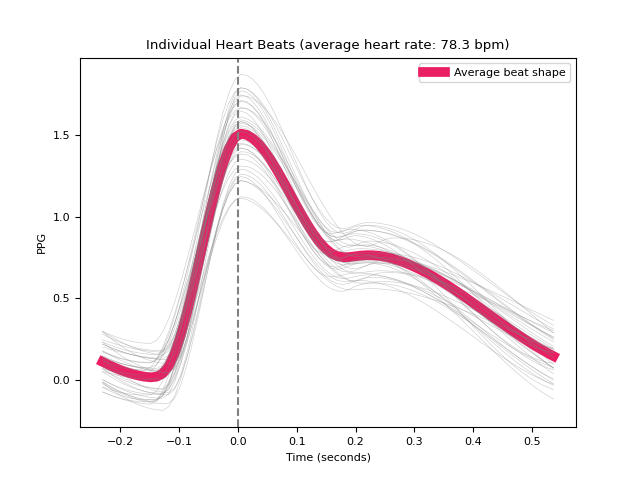
- ppg_segment(ppg_cleaned, peaks=None, sampling_rate=1000, show=False, **kwargs)[source]#
Segment a PPG signal into single heartbeats
Segment a PPG signal into single heartbeats. Convenient for visualizing all the heart beats.
- Parameters:
ppg_cleaned (Union[list, np.array, pd.Series]) – The cleaned PPG channel as returned by
ppg_clean().peaks (dict) – The samples at which the R-peaks occur. Dict returned by
ppg_peaks(). Defaults toNone.sampling_rate (int) – The sampling frequency of
ppg_cleaned(in Hz, i.e., samples/second). Defaults to 1000.show (bool) – If
True, will return a plot of heartbeats. Defaults toFalse.**kwargs – Other arguments to be passed.
- Returns:
dict – A dict containing DataFrames for all segmented heartbeats.
Examples
In [1]: import neurokit2 as nk In [2]: ppg = nk.ppg_simulate(duration=30, sampling_rate=100, heart_rate=80) In [3]: ppg_epochs = nk.ppg_segment(ppg, sampling_rate=100, show=True)